一,、概述

32路同步數(shù)據(jù)采集系統(tǒng)可以完成32路數(shù)據(jù)的同步采集,、存儲以及實時信號處理等功能,,適用于實驗室振動狀態(tài)在線檢測、噪聲檢測,、溫度試驗、環(huán)境試驗,、雷管引爆延遲時間檢測等應(yīng)用,。
32路同步數(shù)據(jù)包括單個板卡通道之間的同步和多個板卡之間的同步,同步后的數(shù)據(jù)先存在板載DDR3,,再通過PCIe接口把數(shù)據(jù)傳輸?shù)缴衔粰C,,如果采集的是瞬態(tài)信號,可以使用Standard模式,,可以把數(shù)據(jù)都存儲在板載DDR3上,,但要求采集的數(shù)據(jù)不能超過板載DDR3存儲容量;如果采集的是連續(xù)信號,,可以使用FIFO模式,,數(shù)據(jù)可以一邊存儲在DDR3上,一邊把數(shù)據(jù)傳輸給上位機,,存儲的時間的長短受限于磁盤容量的大小,。
PCIe高速采集存儲系統(tǒng)由數(shù)據(jù)采集模塊,、高速數(shù)據(jù)存儲模塊、GPU實時處理模塊,、便攜式工控機等部分組成,。可以實現(xiàn)信號的實時采集存儲,,并且通過調(diào)用Window API的方式實現(xiàn)了比一般方式更快的數(shù)據(jù)存儲速度,。
二、應(yīng)用方向
具備多次觸發(fā)的連續(xù)數(shù)據(jù)流模式
可長時間進行雷達信號仿真和模擬
具備多次觸發(fā)的連續(xù)數(shù)據(jù)流模式
觸發(fā)間底死區(qū)時間(<80ns)
時域和頻域分析
高級顯示模式
連續(xù)數(shù)據(jù)流存儲
超高的數(shù)據(jù)傳輸速度(>3.4GB/s)
高采樣率和高分辨率
時域和頻域分析
低噪聲模擬信號調(diào)理電路
低噪聲與高分辨率
高SNR(>90dB)與SFDR(>105dB)
上百個同步通道
高SNR(>90dB)與SFDR(>105dB)
功能齊全的模擬信號調(diào)理電路
5GS/s采樣率與寬帶寬
板載分塊統(tǒng)計,、峰值檢測功能
三,、術(shù)語說明
|
PCIe
|
是新的總線和接口標準,PCIe屬于高速串行點對點雙通道高帶寬傳輸,,所連接的設(shè)備分配獨享通道帶寬,,不共享總線帶寬,主要支持主動電源管理,,錯誤報告,,端對端的可靠性傳輸,熱插拔以及服務(wù)質(zhì)量(QOS)等功能,。PCIe交由PCI-SIG(PCI特殊興趣組織)認證發(fā)布后才改名為“PCI-Express”,,簡稱“PCI-E”。
|
|
DMA
|
(Direct Memory Access,,直接內(nèi)存存取) 是所有現(xiàn)代電腦的重要特色,,它允許不同速度的硬件裝置來溝通,而不需要依于 CPU 的大量中斷負載,。
|
|
ADC
|
模擬到數(shù)字式轉(zhuǎn)換器
|
|
CreateFile
|
是一個多功能的函數(shù),,可打開或創(chuàng)建以下對象,并返回可訪問的句柄:控制臺,,通信資源,,目錄(只讀打開),磁盤驅(qū)動器,,文件,郵槽,,管道,。
|
|
ReadFile
|
從文件指針指向的位置開始將數(shù)據(jù)讀出到一個文件中,且支持同步和異步操作如果文件打開方式?jīng)]有指明FILE_FLAG_OVERLAPPED的話,,當程序調(diào)用成功時,,它將實際讀出文件的字節(jié)數(shù)保存到lpNumberOfBytesRead指明的地址空間中。
|
|
WriteFile
|
WriteFile函數(shù)將數(shù)據(jù)寫入一個文件,。該函數(shù)比fwrite函數(shù)要靈活的多,。也可將這個函數(shù)應(yīng)用于對通信設(shè)備,、管道、套接字以及郵槽的處理
|
|
fwrite
|
fwrite是C語言函數(shù),,指向文件寫入一個數(shù)據(jù)塊,。
|
|
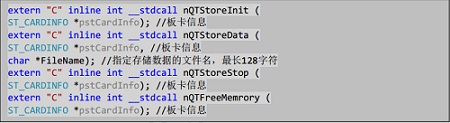
nQTStoreInit
|
輸入?yún)?shù)為板卡信息塊,通過調(diào)用此接口申請好 Ping-Pang buffer,。
|
|
nQTStoreData
|
根據(jù)用戶指定的文件名創(chuàng)建好文件,,并且開始采集存儲。
|
|
nQTStoreStop
|
停止采集和存儲,。
|
|
nQTFreeMemory
|
釋放 Ping-Pang buffer 的內(nèi)存,。
|
四、環(huán)境說明
硬件平臺
微星X99A SLI PLUS主板
Intel i7-5820k 處理器
金士頓 8GB DDR4 內(nèi)存x4

Spectrum M2i.4912:8通道,,16bit,,10MS/s采樣率AD采集卡
±200mV到±10V軟件可調(diào)增益設(shè)置
50歐姆或1M歐姆輸入阻抗
板載高穩(wěn)定度采集時鐘發(fā)生器,支持外時鐘和外觸發(fā)同步輸入
PCIe2.0 x1接口
512MB板載內(nèi)存
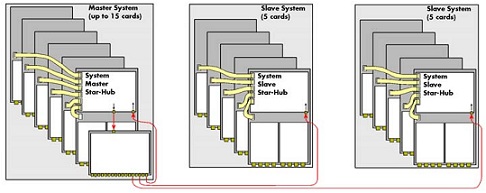
Star-Hub實現(xiàn)多板卡同步:

NVIDIA GeForce GTX 980
Maxwell架構(gòu)
支持CUDA 并行處理
CUDA處理器核心達2048
4TB RAID0磁盤陣列
連續(xù)存儲速度可達1.2GB/s
磁盤陣列由4塊1TB三星固態(tài)硬盤組成,,每個固態(tài)硬盤支持大500MS/s(實測)的寫入速度,,組成RAID0陣列后支持大1.2GB/s(實測)的寫入速度。RAID0磁盤沒有奇偶數(shù)目的要求,,數(shù)據(jù)被平均分割存儲到多個磁盤上,,總的讀寫速度就是磁盤數(shù)量乘以單個磁盤的讀寫速度,缺點在于一塊磁盤損壞,,則整個磁盤陣列即壞,,數(shù)據(jù)無法被修復(fù)。
軟件平臺
- Win7 x64操作系統(tǒng)
- SBench6操作軟件
Control Center:Control center是spectrum公司的專有的控制采集卡校準,、license激活,、底層kernel控制的軟件。啟動control center有Kernel Register Settings,,可以設(shè)置底層kernel開辟的物理連續(xù)地址空間,,用于DMA大數(shù)據(jù)量存儲使用。
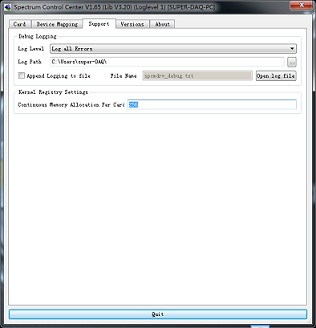
我們知道,,目前的操作系統(tǒng)中,,非常嚴格的把物理存儲空間、內(nèi)核存儲空間,、上層用戶存儲空間區(qū)分開來,。
Windows操作系統(tǒng)對內(nèi)存的管理是按照4kByte來進行的。
對于軟件來說,,申請到的虛擬內(nèi)存都是通過內(nèi)存管理單元每4kByte來進行分配的,。對于上位機軟件來說,分配1個很大的內(nèi)存空間,,在虛擬內(nèi)存上是連續(xù)的,,但是在物理地址上有可能是很多個獨立的4kByte組成的,。
當使用虛擬的內(nèi)存來進行DMA傳輸數(shù)據(jù)的時候,這個過程是非常復(fù)雜的,。
因為,,DMA傳輸數(shù)據(jù)是直接通過物理地址傳遞的,這樣DMA傳輸就得通過每個獨立的4kByte的頁來進行傳輸,,這樣每次DMA傳輸?shù)臄?shù)據(jù)都是在不同物理地址4kByte頁上切換到降低DMA傳輸?shù)男省?/span>
Spectrum kernel driver:Spectrum公司通過自己底層驅(qū)動,,可以通過軟件向底層申請開辟一段物理地址連續(xù)的地址空間,申請完,,需要重啟電腦,,重啟電腦,在PC機boot的過程中,,需要多花費平時的80%的啟動時間,。
五、總體設(shè)計
硬件總體框架:
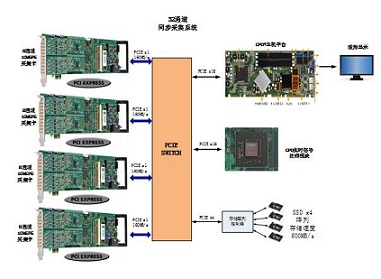
數(shù)據(jù)采集系統(tǒng)在FIFO模式下數(shù)據(jù)的傳輸存儲速度主要受限于PCIE接口的傳輸速度與磁盤的寫入速度,。
本系統(tǒng)數(shù)據(jù)采集卡采用PCIex1 Gen2.0接口,,數(shù)據(jù)傳輸速度可達160MB/s。采集卡為16bit,,采樣率高為10MS/s,,這時單個采集卡在FIFO模式下需傳輸?shù)臄?shù)據(jù)量為:
16bit/2*10MS/s*8=160MB/s
恰好達到PCIe接口的極限速度。采集到的信號在寫入磁盤時總的數(shù)據(jù)量為:
160MB/s*4=640MB/s
寫入速度超過單個固態(tài)硬盤的寫入速度,,但使用RAID0陣列時,,則可以滿足寫入的需求。
六,、高速存儲模塊
限制文件存儲速度的終瓶頸還是磁盤的固有特性,,我們所能做到只是改善軟件的實現(xiàn)去逼近硬盤的極限讀寫速度。一般windows系統(tǒng)粘貼拷貝文件的時候,,影響存儲速度地方就在于它利用了windows文件緩存機制,,當你拷貝一個大文件時,windows會根據(jù)你要拷貝的文件大小緩存很大一部分到系統(tǒng)緩存,,這時候你會看到系統(tǒng)緩存瞬間飆漲,,機器性能大大降低,所以我們要避免使用windows緩存機制,,并且盡量讀寫連續(xù)的文件塊,。
利用Window API讀寫文件
一般來說,我們操作一個windows I/O句柄用的是windows文件讀寫系列API:CreateFile, ReadFile, WriteFile等,,這些API不僅可以讀寫文件句柄,所有的I/O設(shè)備句柄都能通過這些API來操作,。比如socket描述符, 串口描述符,,管道描述符等,。通過設(shè)置他們的參數(shù),我們可以選擇以不同的方式操作IO,。
對于讀寫速度,重要的是dwFlagsAndAttrib參數(shù),FILE_FLAG_NO_BUFFERING指示系統(tǒng)不使用快速緩沖區(qū)或緩存,,當和FILE_FLAG_OVERLAPPED組合,,該標志給出大的異步操作量,因為I/O不依賴內(nèi)存管理器的異步操作,。然而,,一些I/O操作將會運行得長一些,因為數(shù)據(jù)沒有控制在緩存中,。
當使用FILE_FLAG_NO_BUFFERING打開文件進行工作時,,程序必須達到下列要求:
1. 文件的存取開頭的字節(jié)偏移量必須是扇區(qū)尺寸的整倍數(shù)。
2. 文件存取的字節(jié)數(shù)必須是扇區(qū)尺寸的整倍數(shù),。例如,,如果扇區(qū)尺寸是512字節(jié)。程序就可以讀或者寫512,,1024或者2048字節(jié),,但不能夠是335,981或者7171字節(jié)。
3. 進行讀和寫操作的地址必須在扇區(qū)的對齊位置,,在內(nèi)存中對齊的地址是扇區(qū),。尺寸的整倍數(shù)。一個將緩沖區(qū)與扇區(qū)尺寸對齊的途徑是使用VirtualAlloc函數(shù),。
它分配與操作系統(tǒng)內(nèi)存頁大小的整倍數(shù)對齊的內(nèi)存地址.這塊內(nèi)存在地址中同樣與扇區(qū)尺寸大小的整倍數(shù)對齊,。程序可以通過調(diào)用GetDiskFreeSpace來確定扇區(qū)的尺寸。
高速采集存儲配置
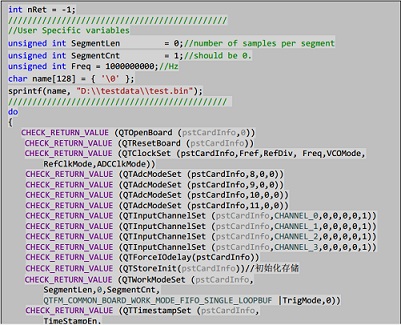
為了實現(xiàn)高速采集存儲,,此處用到了windows多線程編程,,一個線程接收板卡采集到的數(shù)據(jù),一個線程負責(zé)寫文件,。為了保證存儲文件的速度需要連續(xù)寫入大文件,,通過申請兩個大小相同的buffer,執(zhí)行ping-pang寫文件操作,。
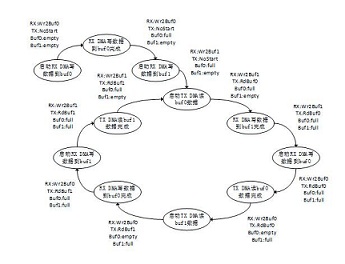
Buf0和Buf1收發(fā)數(shù)據(jù)為ping-pang原理,,Buf0和Buf1的狀態(tài)為empty和full,當數(shù)據(jù)通過TX DMA讀出后,,Buf的狀態(tài)置為empty,,當數(shù)據(jù)通過RX DMA寫入后,Buf的狀態(tài)置為full,。RX DMA和TX DMA的狀態(tài)分別有WrBuf0,,WrBuf1,,RdBuf0,RdBuf1,,OpCmpt,,NotStart,TXHungry0,,TXHungry1幾種狀態(tài),。
對于ADC接收數(shù)據(jù)方向,RX DMA寫buf0產(chǎn)生完成中斷后,,首先開始寫buf1操作,,然后建立寫buf0的DMA接收鏈表。同樣當RX DMA寫buf1產(chǎn)生完成中斷后,,首先開始寫buf0操作,,然后建立寫buf1的DMA接收鏈表。
對于PCIE發(fā)送數(shù)據(jù)方向,,TX DMA讀buf0產(chǎn)生完成中斷后,,首先開始讀buf1操作,然后建立讀buf0的DMA發(fā)送鏈表,。同樣當TX DMA讀buf1產(chǎn)生完成中斷后,,首先開始讀buf0操作,然后建立讀buf1的DMA發(fā)送鏈表,。
根據(jù)PC機實際內(nèi)存大小,,設(shè)置相應(yīng)的buffer大小,buffer需要盡可能大,。通過API工程里面的宏定義設(shè)置buffer的大小,。

另外幾個與高速存儲相關(guān)的API如下圖:
nQTStoreInit輸出參數(shù)為板卡信息塊,通過調(diào)同此接口申請好Ping-Pang buffer,,由于運行時間較長,,所以建議放置在配置過程中執(zhí)行。nQTStoreData創(chuàng)建好文件,,并且開始采集存儲,。在執(zhí)行了一段時間的采集后可以通過調(diào)用nQTStoreStop來停止采集和存儲。值得注意的是程序通過Ping-Pang機制存儲所以會導(dǎo)致后得到的文件大小是Buffer大小的整數(shù)倍,,但是會保證上位機獲取到的數(shù)據(jù)全部都存入到文件中,。為了實現(xiàn)循環(huán)開始存儲,停止存儲操作,,避免此過程中內(nèi)存的重復(fù)申請與釋放導(dǎo)致降低效率,,把內(nèi)存釋放的操作以下API中:
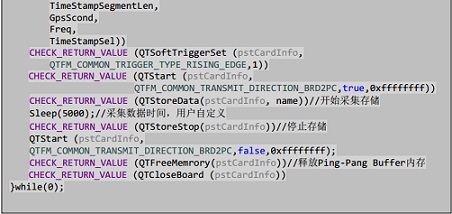
在程序運行的結(jié)尾,通過調(diào)用nQTFreeMemrory來釋放Ping-Pang buffer的內(nèi)存。這樣就完成了從打開板卡進行數(shù)據(jù)采集到數(shù)據(jù)存儲到工控機硬盤中的全過程,。
與一般存儲方式速度對比
一般存儲方式通過調(diào)用C語言中的fwrite進行寫數(shù)據(jù)的操作,,但這樣的方式在數(shù)據(jù)量巨大的情況下與Writefile這種調(diào)用Windows API方式進行對比時速度差異明顯,在使用Writefile方式進行大量數(shù)據(jù)寫入時速度可逼近硬盤的寫入速度,。
下圖為寫入1GB數(shù)據(jù)時使用fwrite進行寫數(shù)據(jù)操作時實測的速度:
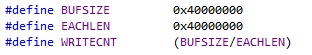
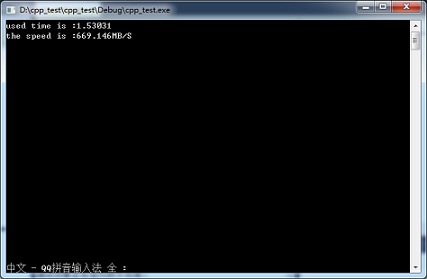
下圖為寫入1GB數(shù)據(jù)時使用WriteFile進行寫數(shù)據(jù)操作時實測的速度:
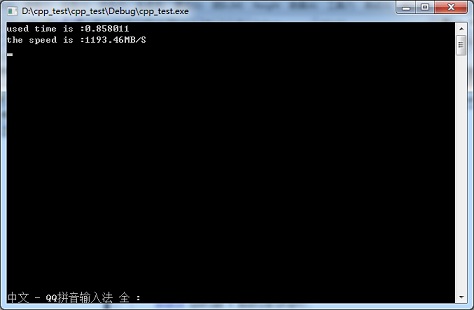
由圖中測試數(shù)據(jù)可知,使用WriteFile進行寫數(shù)據(jù)時速度可達1193.46MB/s,,遠遠快于使用fwrite時669.146MB/s的寫入速度,。當寫入的數(shù)據(jù)量越大時,WriteFile的優(yōu)勢越明顯,,直至逼近磁盤陣列的極限速度,。
七、GPU分析處理模塊
NVIDIA GPU介紹
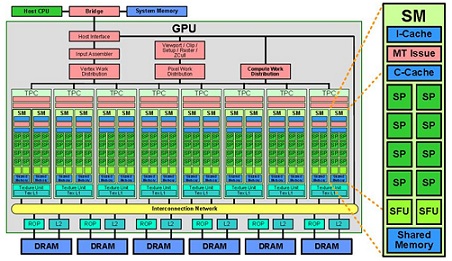
圖形處理單元CPU英文全稱Graphic Processing Unit,,GPU是相對于CPU的一個概念,,NVIDIA公司在1999年發(fā)布GeForce256圖形處理芯片時首先提出GPU的概念。GPU使顯卡減少了對CPU的依賴,,并進行部分原本CPU的工作,,主要是并行計算部分。CPU具有強大的浮點數(shù)編程和計算能力,,在計算吞吐量和內(nèi)存帶寬上,,現(xiàn)代的GPU遠遠超過CPU。
使用NVIDIA CUDA Fast Fourier Transform Library提供了一個簡單計算FFT運算的接口,,而不用用戶自己實現(xiàn)FFT算法,。
GPU內(nèi)存管理
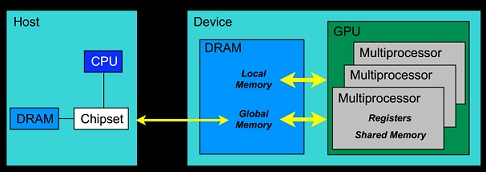
Host: 將CPU及系統(tǒng)的內(nèi)存稱為主機
Device: 將GPU及GPU本身的顯示內(nèi)存稱為設(shè)備
cudaMalloc(): 與C語言中的malloc函數(shù)一樣,用戶函數(shù)分配線性內(nèi)存空間,。
cudaMemcpy():與C語言中的memcpy函數(shù)一樣,,只是此函數(shù)可以在主機內(nèi)存和GPU內(nèi)存之間互相拷貝數(shù)據(jù)。
cudaFree(): 與C語言中的free函數(shù)一樣,,只是此函數(shù)釋放的是
cudaMalloc: 分配的內(nèi)存,,主要用于釋放線性內(nèi)存空間。
CPU與GPU進行FFT分析速度對比
lCPU FFT分析
MATLAB對10M Sample的數(shù)據(jù)進行FFT運算,,時間0.594697s,,如下圖:
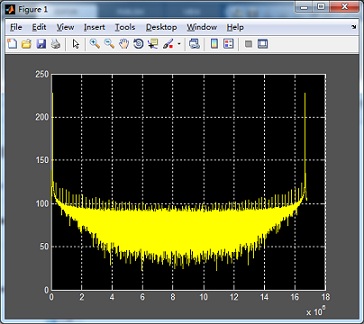
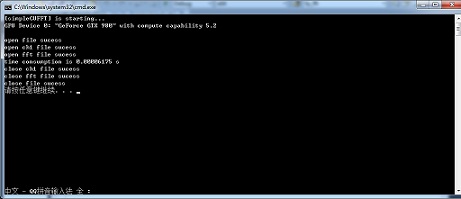
lGPU FFT分析
使用GPU進行FFT計算,FFT點數(shù)10M Sample,,運行時間0.00006175s,。
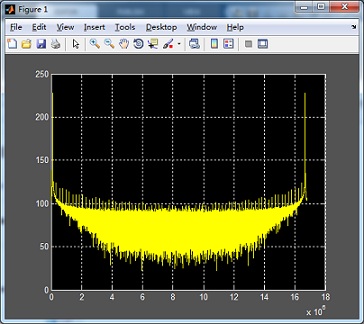
對GPU FFT運算之后的結(jié)果,10M個實部real和10M個虛部imag,,用MATLAB進行仿真,,如下圖:












































頁廣告7")



